Réplication ZFS et serveur NFS hautement disponible
Documentation de mon infrastructure de stockage hybride : stockage distribué Linstor DRBD pour les VM, et réplication ZFS active-passive pour les données froides avec serveur NFS hautement disponible.
Contexte et problématique
Architecture de stockage hybride
Mon cluster Proxmox utilise deux types de stockage aux besoins et contraintes différents :
Stockage haute performance pour VM/LXC : Linstor DRBD
- Usage : Disques système des machines virtuelles et conteneurs
- Besoins : Réplication synchrone, live migration, RPO ~0
- Support : SSD NVMe sur les nœuds Proxmox
- Technologie : Linstor DRBD (voir article de blog sur le stockage distribué)
Stockage de données froides : ZFS répliqué
- Usage : Médias, fichiers utilisateurs, backups Proxmox Backup Server
- Besoins : Capacité importante, intégrité des données, disponibilité élevée mais live migration non requise
- Support : Disques USB sur les nœuds Proxmox (pools ZFS indépendants)
- Technologie : Réplication ZFS active-passive avec Sanoid/Syncoid
Pourquoi ne pas utiliser Linstor DRBD pour tout ?
Le stockage distribué synchrone comme Linstor DRBD présente plusieurs contraintes pour des données froides :
- Performance d'écriture : Chaque écriture doit être confirmée sur plusieurs nœuds, ce qui pénalise les transferts de gros fichiers
- Consommation réseau : La réplication synchrone saturerait le réseau 1 Gbps lors de transferts massifs
- Complexité inutile : Les données froides n'ont pas besoin de live migration ni de RPO proche de zéro
- Coût/bénéfice : Sur-consommation de ressources pour un besoin qui peut être satisfait par de la réplication asynchrone
La solution : réplication active-passive ZFS
Pour les données froides, une réplication asynchrone par snapshots offre le meilleur compromis :
| Critère | Linstor DRBD | ZFS répliqué |
|---|---|---|
| Type de réplication | Synchrone | Asynchrone (snapshots) |
| Overhead réseau | Élevé (continu) | Faible (par intervalles) |
| RPO | ~0 | Intervalle snapshots (10 min) |
| Live migration | Oui | Non nécessaire |
| Intégrité données | Bonne | Excellente (checksums ZFS) |
| Adapté pour | VM/LXC système | Données froides volumineuses |
Un RPO de 10 minutes est parfaitement acceptable pour des médias et fichiers utilisateurs : en cas de panne d'un nœud, seules les modifications des 10 dernières minutes pourraient être perdues.
Architecture
Vue d'ensemble
┌─────────────────────────────────────────────────────────────┐
│ Cluster Proxmox HA │
│ │
│ ┌──────────────────┐ ┌──────────────────┐ │
│ │ acemagician │ │ elitedesk │ │
│ │ │◄────────────►│ │ │
│ │ - zpool1 (10TB) │ Réplication │ - zpool1 (10TB) │ │
│ │ - zpool2 (2TB) │ Sanoid/ │ - zpool2 (2TB) │ │
│ │ │ Syncoid │ │ │
│ └────────┬─────────┘ └─────────┬────────┘ │
│ │ │ │
│ │ ┌──────────────┐ │ │
│ └────────►│ LXC 103 │◄────────┘ │
│ │ NFS Server │ │
│ │ (rootfs sur │ │
│ │ DRBD) │ │
│ └──────┬───────┘ │
└────────────────────────────┼──────────────────────────────┘
│
▼
Clients NFS (VMs)
192.168.100.0/24
Composants
Pools ZFS sur les nœuds Proxmox
Chaque nœud dispose de deux pools ZFS indépendants :
zpool1 (~10 TB) : Données volumineuses
zpool1/data-nfs-share: Partage NFS principal (6.83 TB utilisés)zpool1/pbs-backups: Backups Proxmox Backup Server
zpool2 (~2 TB) : Médias et fichiers
zpool2/photos: Photothèque (14.7 GB)zpool2/storage: Fichiers divers (19.1 GB)
État des pools sur les nœuds :
# Nœud acemagician
root@acemagician:~# zfs list
NAME USED AVAIL REFER MOUNTPOINT
zpool1 7.83T 2.95T 104K /zpool1
zpool1/data-nfs-share 6.83T 2.95T 6.79T /zpool1/data-nfs-share
zpool1/pbs-backups 96K 1024G 96K /zpool1/pbs-backups
zpool2 33.9G 1.72T 104K /zpool2
zpool2/photos 14.7G 1.72T 12.7G /zpool2/photos
zpool2/storage 19.1G 1.72T 19.1G /zpool2/storage
# Nœud elitedesk
root@elitedesk:~# zfs list
NAME USED AVAIL REFER MOUNTPOINT
zpool1 7.83T 2.97T 96K /zpool1
zpool1/data-nfs-share 6.83T 2.97T 6.79T /zpool1/data-nfs-share
zpool1/pbs-backups 96K 1024G 96K /zpool1/pbs-backups
zpool2 33.9G 1.72T 112K /zpool2
zpool2/photos 14.7G 1.72T 12.7G /zpool2/photos
zpool2/storage 19.1G 1.72T 19.1G /zpool2/storage
On constate que les pools sont parfaitement synchronisés entre les deux nœuds, avec des tailles identiques pour chaque dataset.
Les pools sont identiques sur les deux nœuds grâce à la réplication bidirectionnelle automatique. Le nœud actif (hébergeant le LXC) est toujours le master.
LXC 103 : Serveur NFS hautement disponible
Le conteneur LXC 103 joue le rôle de serveur NFS avec les caractéristiques suivantes :
- Rootfs sur Linstor DRBD : Permet la haute disponibilité via Proxmox HA
- Montage des datasets ZFS : Accès direct aux pools du nœud hôte via bind mount
- Service NFS : Expose les datasets via NFS aux clients du réseau
- Basculement automatique : En cas de panne, Proxmox HA redémarre le LXC sur l'autre nœud (~60s de downtime)
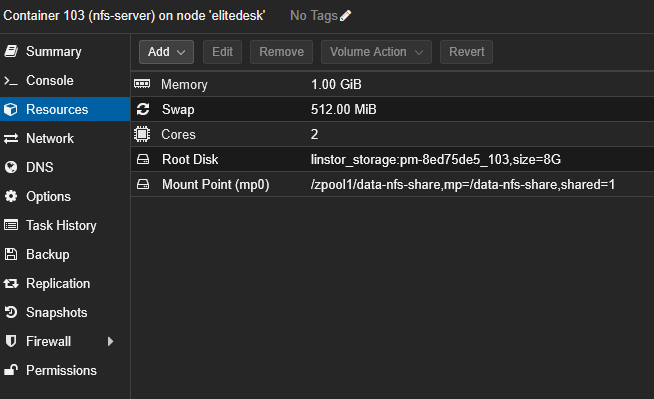
Configuration détaillée :
- CPU : 2 cœurs
- RAM : 1 Go (+ 512 Mo swap)
- Rootfs : 8 Go sur
linstor_storage(stockage distribué DRBD) - Mount Point (mp0) :
/zpool1/data-nfs-share,mp=/data-nfs-share,shared=1
L'option shared=1 est obligatoire pour le bind mount du dataset ZFS. Cette option indique à Proxmox VE que ce stockage est partagé entre les nœuds du cluster, permettant ainsi à la haute disponibilité (HA) de fonctionner correctement sans être bloquée
Le rootfs du conteneur NFS est stocké sur Linstor DRBD pour bénéficier de la haute disponibilité Proxmox. Cela permet au LXC de basculer automatiquement sur l'autre nœud en cas de panne, avec un temps d'arrêt d'environ 60 secondes seulement.
Sans stockage partagé/distribué, Proxmox HA ne pourrait pas migrer automatiquement le conteneur, nécessitant une intervention manuelle.
Script de réplication automatique
Le script zfs-nfs-replica.sh s'exécute toutes les 10 minutes via un timer systemd et implémente la logique suivante :
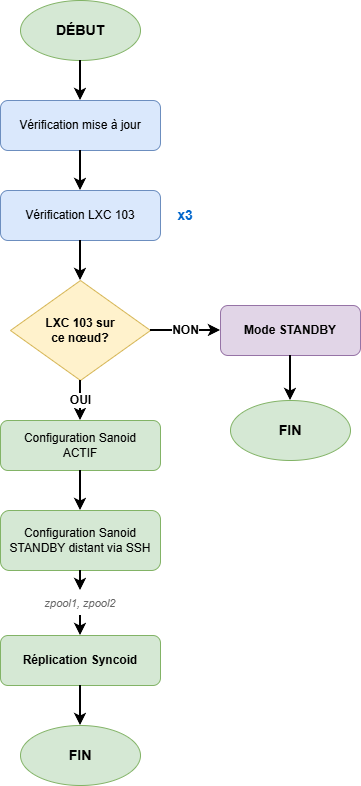
- Détection automatique du master : Le nœud hébergeant le LXC 103 devient automatiquement le master
- Configuration dynamique de Sanoid :
- Nœud master :
autosnap=yes,autoprune=yes(création de snapshots) - Nœud standby :
autosnap=no,autoprune=yes(réception seule)
- Nœud master :
- Réplication via Syncoid : Transfert incrémental des snapshots du master vers le standby
- Vérifications de sécurité :
- Triple vérification que le bon nœud est master
- Comparaison des tailles pour détecter un disque de remplacement vide
- Historique des tailles pour éviter les écrasements accidentels
Fonctionnement technique
Détection automatique du nœud master
Le script détermine quel nœud héberge le LXC 103 :
# Détection du nœud actif
ACTIVE_NODE=$(pvesh get /cluster/resources --type vm --output-format json | \
jq -r '.[] | select(.vmid==103) | .node')
# Comparaison avec le nœud local
CURRENT_NODE=$(hostname)
if [ "$ACTIVE_NODE" = "$CURRENT_NODE" ]; then
# Ce nœud est le master
configure_as_master
else
# Ce nœud est en standby
configure_as_standby
fi
Cette détection garantit que le système s'adapte automatiquement aux migrations du LXC, qu'elles soient planifiées (maintenance) ou automatiques (failover Proxmox HA).
Configuration dynamique de Sanoid
Sanoid est configuré différemment selon le rôle du nœud :
Nœud master (héberge le LXC 103)
[zpool1/data-nfs-share]
use_template = production
recursive = yes
autosnap = yes # Création automatique de snapshots
autoprune = yes # Nettoyage des anciens snapshots
[zpool2/photos]
use_template = production
recursive = yes
autosnap = yes
autoprune = yes
[zpool2/storage]
use_template = production
recursive = yes
autosnap = yes
autoprune = yes
Nœud standby
[zpool1/data-nfs-share]
use_template = production
recursive = yes
autosnap = no # Pas de création de snapshots
autoprune = yes # Nettoyage des anciens snapshots
[zpool2/photos]
use_template = production
recursive = yes
autosnap = no
autoprune = yes
[zpool2/storage]
use_template = production
recursive = yes
autosnap = no
autoprune = yes
Réplication avec Syncoid
Syncoid effectue la réplication incrémentale des snapshots du master vers le standby :
# Réplication de chaque dataset
syncoid --no-sync-snap --recursive \
root@master:zpool1/data-nfs-share \
zpool1/data-nfs-share
syncoid --no-sync-snap --recursive \
root@master:zpool2/photos \
zpool2/photos
syncoid --no-sync-snap --recursive \
root@master:zpool2/storage \
zpool2/storage
L'option --no-sync-snap évite la création d'un snapshot de synchronisation supplémentaire, utilisant uniquement les snapshots Sanoid existants.
Mécanismes de sécurité
Le script implémente plusieurs vérifications pour éviter les pertes de données :
Triple vérification du sens de réplication
Avant chaque réplication, le script vérifie trois fois que :
- Le LXC 103 est bien sur le nœud local
- Le nœud local est bien le master
- La configuration Sanoid est bien en mode master
Si l'une de ces vérifications échoue, la réplication est abandonnée pour éviter une réplication dans le mauvais sens.
Protection contre les disques vides
Avant de répliquer, le script compare la taille des datasets :
# Récupération des tailles
SOURCE_SIZE=$(ssh root@master "zfs get -Hp -o value used zpool1/data-nfs-share")
TARGET_SIZE=$(zfs get -Hp -o value used zpool1/data-nfs-share)
# Si le source est significativement plus petit que la cible
if [ $SOURCE_SIZE -lt $(($TARGET_SIZE / 2)) ]; then
echo "ERREUR: Taille source suspecte, disque de remplacement vide ?"
exit 1
fi
Cela évite qu'un disque de remplacement vide n'écrase les données du standby.
Historique des tailles
Le script maintient un historique des tailles de datasets pour détecter des variations anormales (chute brutale de taille indiquant un problème).
Configuration NFS
Exports NFS sur le LXC 103
Le fichier /etc/exports définit les partages NFS :
# Pools zpool2 exposés à une VM spécifique (192.168.100.250)
/zpool2 192.168.100.250(sync,wdelay,hide,crossmnt,no_subtree_check,sec=sys,rw,secure,no_root_squash,no_all_squash)
/zpool2/photos 192.168.100.250(sync,wdelay,hide,crossmnt,no_subtree_check,sec=sys,rw,secure,no_root_squash,no_all_squash)
/zpool2/storage 192.168.100.250(sync,wdelay,hide,crossmnt,no_subtree_check,sec=sys,rw,secure,no_root_squash,no_all_squash)
# Partage principal accessible à tout le réseau
/data-nfs-share 192.168.100.0/24(sync,wdelay,hide,no_subtree_check,sec=sys,rw,insecure,no_root_squash,no_all_squash)
Options NFS expliquées
| Option | Description |
|---|---|
sync | Confirme les écritures uniquement après commit sur disque (intégrité) |
wdelay | Regroupe les écritures pour améliorer les performances |
hide | Cache les sous-montages des clients NFS v3 |
crossmnt | Permet de traverser les montages (utile avec les datasets ZFS) |
no_subtree_check | Désactive la vérification des sous-arborescences (performance) |
rw | Lecture/écriture |
secure | Exige que les requêtes proviennent de ports < 1024 (sécurité) |
insecure | Autorise les ports > 1024 (nécessaire pour certains clients) |
no_root_squash | Préserve les permissions root (évite le mapping vers nobody) |
no_all_squash | Préserve les UIDs/GIDs des utilisateurs |
L'option no_root_squash permet aux clients NFS d'effectuer des opérations en tant que root. Cela est acceptable dans un réseau domestique de confiance (192.168.100.0/24), mais constituerait un risque de sécurité majeur sur un réseau non maîtrisé.
Services systemd
Services NFS actifs sur le LXC :
nfs-server.service enabled # Serveur NFS principal
nfs-blkmap.service enabled # Support pNFS block layout
nfs-client.target enabled # Cible pour les clients NFS
Ports réseau
Ports NFS en écoute :
2049/tcp # NFSv4 (principal)
111/tcp # Portmapper (rpcbind)
Montage NFS côté client
Configuration /etc/fstab
Pour monter automatiquement le partage NFS au démarrage d'une VM ou conteneur, ajouter l'entrée suivante dans /etc/fstab :
192.168.100.150:/data-nfs-share /mnt/storage nfs hard,intr,timeo=100,retrans=30,_netdev,nofail,x-systemd.automount 0 0
Cette configuration est utilisée sur ma VM de production Docker Compose & Ansible qui héberge l'ensemble de mes services conteneurisés.
Options de montage expliquées
| Option | Description |
|---|---|
hard | En cas d'indisponibilité du serveur NFS, les opérations I/O sont bloquées en attente plutôt que d'échouer (garantit l'intégrité) |
intr | Permet d'interrompre les opérations I/O bloquées avec Ctrl+C (utile en cas de problème réseau) |
timeo=100 | Timeout de 10 secondes (100 dixièmes de seconde) avant de retry |
retrans=30 | Nombre de retransmissions avant de déclarer une erreur (30 × 10s = 5 minutes de retry) |
_netdev | Indique que le montage nécessite le réseau (systemd attend la connectivité réseau) |
nofail | N'empêche pas le boot si le montage échoue (évite un blocage au démarrage) |
x-systemd.automount | Montage automatique à la première utilisation (évite de bloquer le boot) |
0 0 | Pas de dump ni de fsck (non applicable pour NFS) |
Comportement lors d'un failover NFS
Grâce aux options hard et retrans=30, lors du basculement du serveur NFS (~60 secondes) :
- Pendant le failover : Les opérations I/O en cours sont suspendues (hard mount)
- Retry automatique : Le client NFS retry pendant 5 minutes (30 × 10s)
- Reprise transparente : Dès que le serveur NFS redémarre sur l'autre nœud, les opérations I/O reprennent automatiquement
- Aucune intervention : Les applications n'ont pas besoin de redémarrer ni de remonter le partage
Le temps de retry (5 minutes) est largement supérieur au RTO du serveur NFS (~60 secondes), garantissant que les clients survivent au failover sans erreur.
Vérification du montage automatique
# Recharger systemd pour prendre en compte le fstab
systemctl daemon-reload
# Tester le montage sans reboot
mount -a
Haute disponibilité et temps de basculement
Architecture HA grâce à Linstor DRBD
Le serveur NFS bénéficie de la haute disponibilité Proxmox grâce au rootfs du LXC 103 stocké sur Linstor DRBD :
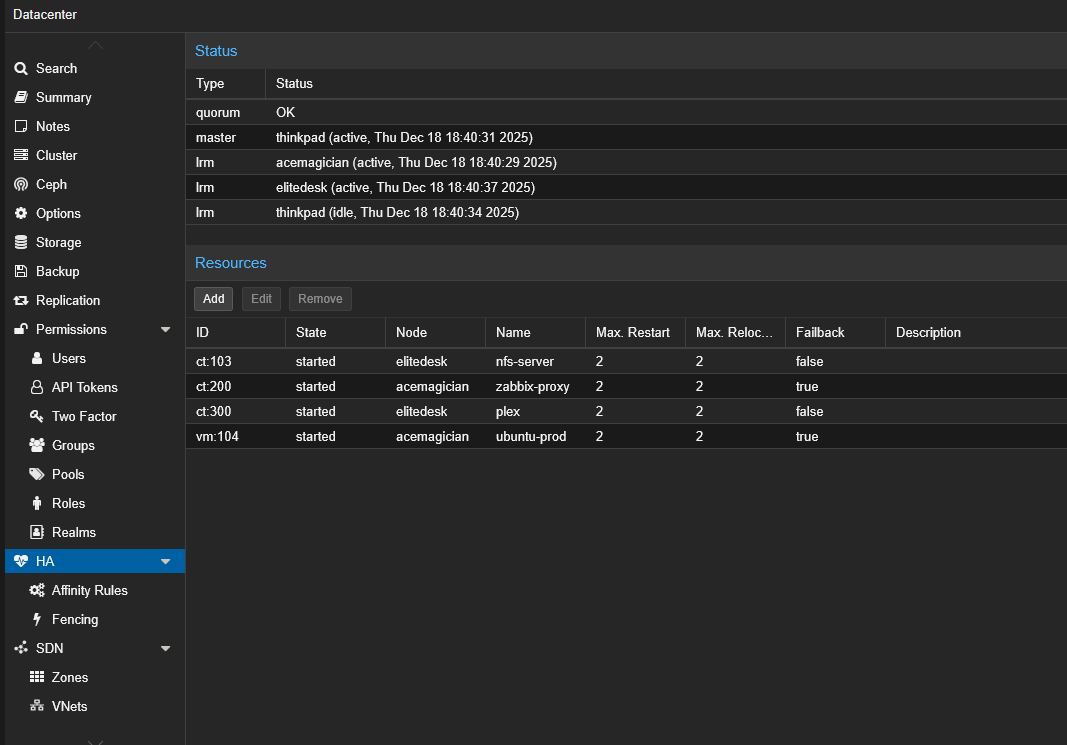
La capture d'écran ci-dessus montre la configuration HA Proxmox du serveur NFS :
- LXC 103 (nfs-server) : Ressource HA avec Max. Restart = 2, actuellement hébergé sur le nœud
elitedesk - Le LXC peut redémarrer automatiquement sur l'autre nœud en cas de panne, grâce à son rootfs sur stockage DRBD partagé
Scénario de panne : failover automatique
En cas de panne d'un nœud hébergeant le LXC 103 :
- Détection (5-10s) : Proxmox HA Manager détecte la panne du nœud via le quorum
- Décision (1-2s) : Le HA Manager d�écide de redémarrer le LXC sur le nœud survivant
- Migration du stockage (0s) : Le rootfs DRBD est déjà répliqué et accessible sur l'autre nœud
- Démarrage du LXC (40-50s) : Le LXC démarre sur le nouveau nœud
- Montage ZFS et démarrage NFS (5-10s) : Les datasets ZFS locaux sont montés et le service NFS démarre
Temps total de basculement : ~60 secondes
- RPO (Recovery Point Objective) : 10 minutes (intervalle de réplication ZFS)
- RTO (Recovery Time Objective) : ~60 secondes (temps de failover du LXC)
Ces valeurs sont largement acceptables pour un serveur NFS de données froides dans un contexte homelab.
Adaptation automatique de la réplication
Après le basculement du LXC sur l'autre nœud :
- Le script de réplication détecte que le LXC est maintenant sur le nouveau nœud
- La configuration Sanoid est automatiquement inversée :
- L'ancien master devient standby (autosnap=no)
- Le nouveau master devient actif (autosnap=yes)
- La réplication s'effectue désormais dans le sens inverse
Aucune intervention manuelle n'est nécessaire.
Installation et déploiement
Prérequis
- Cluster Proxmox avec au moins 2 nœuds
- Pools ZFS identiques sur chaque nœud
- LXC avec rootfs sur stockage partagé/distribué (Linstor DRBD)
- Sanoid et Syncoid installés sur les nœuds Proxmox
- Accès SSH entre les nœuds (clés SSH configurées)
Installation du script
# Sur chaque nœud Proxmox
# 1. Cloner le dépôt Git
cd /tmp
git clone https://forgejo.tellserv.fr/Tellsanguis/zfs-sync-nfs-ha.git
cd zfs-sync-nfs-ha
# 2. Installer le script
cp zfs-nfs-replica.sh /usr/local/bin/
chmod +x /usr/local/bin/zfs-nfs-replica.sh
# 3. Installer les services systemd
cp zfs-nfs-replica.service /etc/systemd/system/
cp zfs-nfs-replica.timer /etc/systemd/system/
# 4. Activer et démarrer le timer
systemctl daemon-reload
systemctl enable --now zfs-nfs-replica.timer
# 5. Nettoyage
cd ..
rm -rf zfs-sync-nfs-ha
Configuration Sanoid de base
Créer /etc/sanoid/sanoid.conf avec le template de production :
[template_production]
frequently = 0
hourly = 24
daily = 7
weekly = 4
monthly = 6
yearly = 0
autosnap = yes
autoprune = yes
Le script modifiera automatiquement les paramètres autosnap selon le rôle du nœud.
Vérification du fonctionnement
# Vérifier l'état du timer
systemctl status zfs-nfs-replica.timer
# Afficher les logs de la dernière exécution
journalctl -u zfs-nfs-replica.service -n 50
# Lister les snapshots Sanoid
sanoid --monitor-snapshots
# Vérifier la réplication sur le standby
zfs list -t snapshot | grep zpool1/data-nfs-share
État des snapshots
root@elitedesk:~# sanoid --monitor-snapshots | grep -E "(zpool1|zpool2)"
OK: all monitored datasets (zpool1, zpool1/data-nfs-share, zpool1/pbs-backups,
zpool2, zpool2/photos, zpool2/storage) have fresh snapshots
Tous les datasets configurés ont des snapshots à jour, confirmant que Sanoid fonctionne correctement.
Logs du service de réplication
Exemple de logs lors d'une exécution réussie sur le nœud master (elitedesk) :
root@elitedesk:~# journalctl -u zfs-nfs-replica.service --since "1 hour ago"
Dec 18 17:44:35 elitedesk systemd[1]: Starting zfs-nfs-replica.service - ZFS NFS HA Replication Service...
Dec 18 17:44:35 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:35] [info] [global] ========================================
Dec 18 17:44:35 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:35] [info] [global] Démarrage du script version 2.0.1
Dec 18 17:44:35 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:35] [info] [global] Nœud: elitedesk
Dec 18 17:44:35 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:35] [info] [global] ========================================
Dec 18 17:44:35 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:35] [info] [global] Vérification des mises à jour depuis https://forgejo.tellserv.fr
Dec 18 17:44:35 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:35] [info] [global] ✓ Script à jour (version 2.0.1)
Dec 18 17:44:35 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:35] [info] [global] Nœud distant configuré: acemagician (192.168.100.11)
Dec 18 17:44:35 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:35] [info] [global] Pools configurés: zpool1 zpool2
Dec 18 17:44:35 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:35] [info] [global] Vérification #1/3 du statut du LXC 103
Dec 18 17:44:37 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:37] [info] [global] Vérification #1/3 réussie: LXC 103 est actif sur ce nœud
Dec 18 17:44:39 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:39] [info] [global] Vérification #2/3 du statut du LXC 103
Dec 18 17:44:41 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:41] [info] [global] Vérification #2/3 réussie: LXC 103 est actif sur ce nœud
Dec 18 17:44:43 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:43] [info] [global] Vérification #3/3 du statut du LXC 103
Dec 18 17:44:45 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:45] [info] [global] Vérification #3/3 réussie: LXC 103 est actif sur ce nœud
Dec 18 17:44:45 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:45] [info] [global] ✓ Triple vérification réussie: le LXC 103 est sur ce nœud
Dec 18 17:44:45 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:45] [info] [global] Configuration de Sanoid en mode ACTIF (autosnap=yes)
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [global] Connexion SSH vers acemagician (192.168.100.11)
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [global] ========================================
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [global] Début de la réplication de 2 pool(s)
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [global] ========================================
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [zpool1] ========================================
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [zpool1] Début de la réplication du pool: zpool1
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [zpool1] ========================================
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [zpool1] Verrou acquis pour zpool1
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [zpool1] Début de la réplication récursive: zpool1
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [zpool1] Vérification des snapshots en commun entre master et standby
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [zpool1] ✓ 209 snapshot(s) en commun trouvé(s)
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [zpool1] Mode: Réplication incrémentale (snapshot le plus récent en commun)
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [zpool1] Datasets à répliquer:
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [zpool1] - zpool1/data-nfs-share
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [zpool1] - zpool1/pbs-backups
Dec 18 17:44:46 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:46] [info] [zpool1] === Réplication de zpool1/data-nfs-share (récursif) ===
Dec 18 17:44:47 elitedesk zfs-nfs-replica[3534180]: NEWEST SNAPSHOT: autosnap_2025-12-18_16:30:10_frequently
Dec 18 17:44:47 elitedesk zfs-nfs-replica[3534180]: INFO: no snapshots on source newer than autosnap_2025-12-18_16:30:10_frequently on target. Nothing to do.
Dec 18 17:44:47 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:47] [info] [zpool1] ✓ zpool1/data-nfs-share répliqué avec succès
Dec 18 17:44:47 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:47] [info] [zpool1] === Réplication de zpool1/pbs-backups (récursif) ===
Dec 18 17:44:47 elitedesk zfs-nfs-replica[3534221]: NEWEST SNAPSHOT: autosnap_2025-12-18_16:30:10_frequently
Dec 18 17:44:47 elitedesk zfs-nfs-replica[3534221]: INFO: no snapshots on source newer than autosnap_2025-12-18_16:30:10_frequently on target. Nothing to do.
Dec 18 17:44:47 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:47] [info] [zpool1] ✓ zpool1/pbs-backups répliqué avec succès
Dec 18 17:44:47 elitedesk zfs-nfs-replica[3533956]: [2025-12-18 17:44:47] [info] [zpool1] Nombre de datasets traités: 2
Points clés visibles dans les logs :
- Triple vérification que le LXC 103 est bien sur le nœud local avant toute réplication
- Configuration automatique de Sanoid en mode ACTIF (autosnap=yes)
- Réplication incrémentale basée sur 209 snapshots communs
- Pas de transfert nécessaire : les datasets sont déjà synchronisés (dernière modification à 16:30, réplication à 17:44)
- Traitement récursif de tous les datasets enfants
Restaurer depuis un snapshot
# Lister les snapshots disponibles
zfs list -t snapshot zpool1/data-nfs-share
# Rollback vers un snapshot spécifique
zfs rollback zpool1/data-nfs-share@autosnap_2025-12-18_12:00:00_hourly
# Ou cloner le snapshot pour inspection
zfs clone zpool1/data-nfs-share@autosnap_2025-12-18_12:00:00_hourly \
zpool1/data-nfs-share-restore
Conclusion
L'architecture de stockage hybride combinant Linstor DRBD et ZFS répliqué offre le meilleur des deux mondes :
- Linstor DRBD pour les VM/LXC : réplication synchrone, live migration, RPO ~0
- ZFS répliqué pour les données froides : capacité importante, intégrité excellente, overhead minimal
Le serveur NFS hautement disponible, avec son rootfs sur DRBD et la réplication automatique ZFS garantit :
- Un temps de basculement de ~60 secondes en cas de panne
- Une adaptation automatique au failover Proxmox HA
- Une perte de données maximale de 10 minutes (RPO)
- Aucune intervention manuelle requise
Cette solution est parfaitement adaptée à un homelab nécessitant haute disponibilité pour un serveur NFS de données froides, tout en conservant des ressources (CPU, RAM, réseau) pour les services critiques.