Première version : le Homelab "HA" monomachine (projet initial)
Introduction
Cette page décrit le projet initial que j'avais envisagé pour expérimenter avec Kubernetes. Ce projet a évolué vers une décision finale différente : un cluster Proxmox 3 nœuds (voir Cluster 3 noeuds Proxmox).
L'idée initiale était de créer une étape transitoire vers une infrastructure distribuée complète, en expérimentant avec Kubernetes (K3S), l'Infrastructure as Code (OpenTofu/Terraform), Git et les pipelines CI/CD, tout en restant sur une seule machine physique.
Objectifs de cette version
Apprentissage pratique
Cette infrastructure monomachine permet d'acquérir une expérience concrète sur :
-
Kubernetes (K3S) :
- Installation et configuration d'un cluster K3S
- Gestion des pods, déploiements, services
- Configuration des ingress controllers
- Gestion du stockage persistant
- Utilisation de Helm pour les déploiements
-
Infrastructure as Code :
- Déclaration de l'infrastructure avec OpenTofu/Terraform
- Versionnement de toute la configuration dans Git
- Modules réutilisables et bonnes pratiques IaC
-
GitOps et CI/CD :
- Intégration avec Forgejo Actions pour les pipelines
- Déploiement automatique sur push Git (GitOps)
- Tests automatisés avant déploiement
- Rollback automatique en cas d'échec
-
Observabilité :
- Stack Prometheus + Grafana pour les métriques
- Loki pour la centralisation des logs
- Alerting et dashboards personnalisés
Validation des concepts
L'objectif était de valider les concepts suivants avant d'investir dans du matériel :
- Valider l'architecture globale
- Tester les configurations Kubernetes
- Affiner les processus de déploiement
- Identifier les services compatibles avec K8S
Évolution du projet : Bien que le serveur devait rester une machine physique unique, l'idée était d'utiliser plusieurs VMs pour simuler un vrai cluster et apprendre les aspects distribués dès le début. Cette approche aurait permis d'expérimenter avec la répartition de charge, la tolérance aux pannes et les politiques d'affinité.
Architecture réseau
Le schéma illustre l'architecture réseau de cette première version :
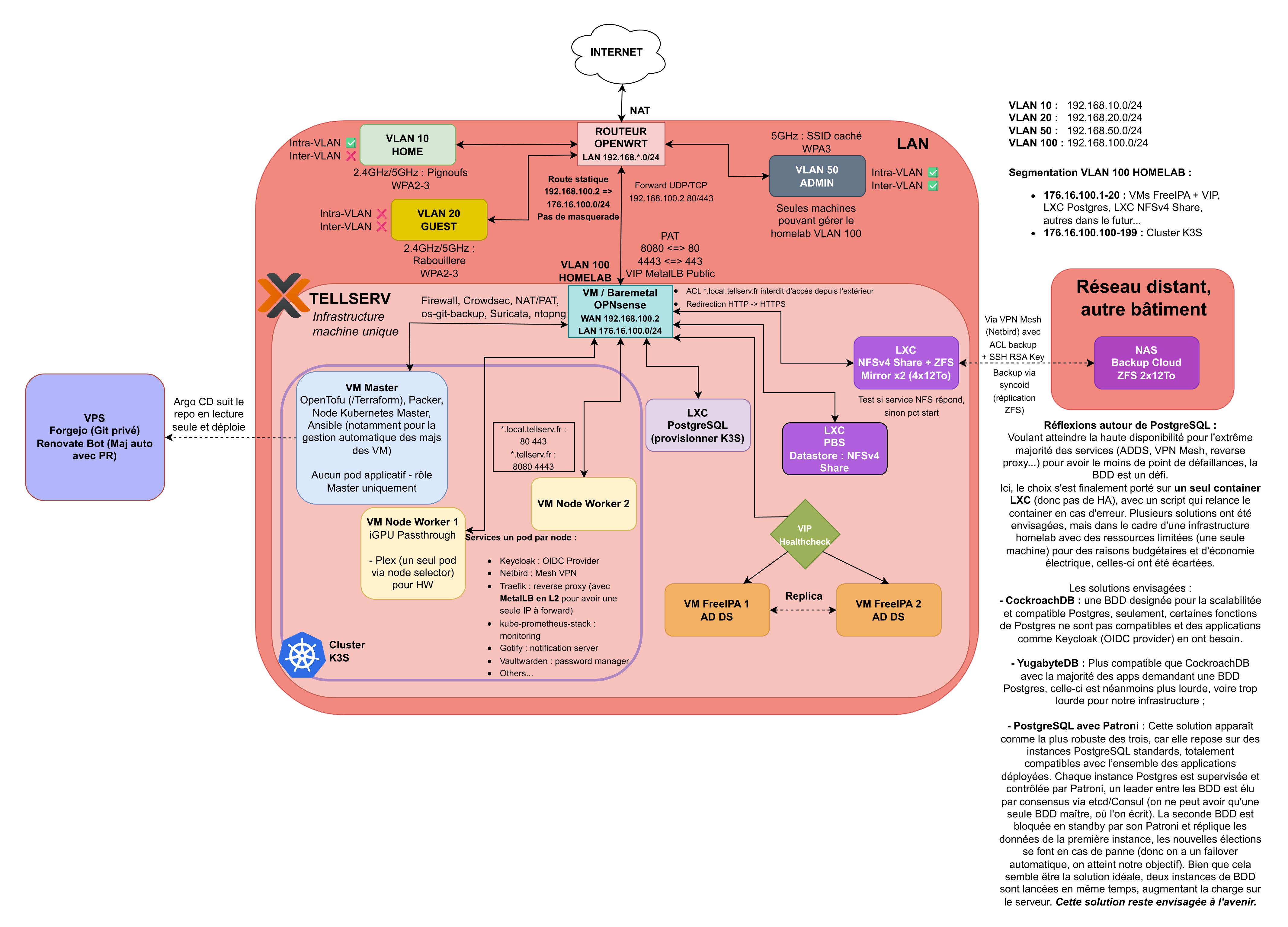
Composants de l'architecture
Infrastructure physique/virtuelle :
- Serveur unique avec ressources suffisantes (16+ GB RAM, 4+ cœurs CPU)
- Stockage local pour les volumes persistants
- Réseau local standard (pas de VLAN segmenté)
Cluster K3S :
- Node unique (control plane + worker combinés)
- Ingress controller (Traefik intégré ou NGINX)
- Local Path Provisioner pour le stockage dynamique
Services déployés :
- Services applicatifs migrés depuis Docker Compose
- Stack d'observabilité (Prometheus, Grafana, Loki)
- ArgoCD pour le GitOps
- Services de test et développement
CI/CD :
- Forgejo avec Actions pour les pipelines
- Déploiements automatiques via ArgoCD
- Tests de validation automatisés
Ce qu'on peut apprendre
Cette infrastructure monomachine permet d'acquérir des compétences essentielles :
Compétences Kubernetes
- Déploiements : Création et gestion de Deployments, StatefulSets, DaemonSets
- Services : LoadBalancer, ClusterIP, NodePort, ExternalName
- Ingress : Configuration du routing HTTP/HTTPS
- ConfigMaps et Secrets : Gestion des configurations et credentials
- Volumes : PersistentVolumes, PersistentVolumeClaims, StorageClasses
- RBAC : Gestion des permissions et rôles
- Namespaces : Isolation logique des applications
- Labels et Selectors : Organisation et sélection des ressources
- Health checks : Liveness, Readiness et Startup probes
Compétences DevOps
- Infrastructure as Code : Déclaration complète de l'infrastructure
- GitOps : Synchronisation automatique Git → Cluster
- CI/CD : Pipelines de test, build et déploiement
- Monitoring : Métriques, alertes, dashboards
- Logging : Centralisation et analyse des logs
- Sécurité : Network Policies, Pod Security Standards
- Helm : Packaging et déploiement d'applications complexes
Compétences en automatisation
- Ansible : Provisioning automatique du serveur et installation K3S
- OpenTofu : Gestion déclarative de l'infrastructure
- Scripts : Automatisation des tâches récurrentes
- Backups : Stratégies de sauvegarde des volumes et états
Limitations de cette approche
1. Pas de vraie haute disponibilité (HA)
Limitation principale : Avec une seule machine, il n'y a pas de redondance :
- Si le serveur tombe en panne, tous les services sont indisponibles
- Pas de basculement automatique (failover)
- Maintenance = downtime obligatoire
- Point unique de défaillance (Single Point of Failure - SPOF)
Ce qui nécessiterait plusieurs nœuds physiques ou VMs :
- Simulation réaliste de pannes réseau entre nœuds
- Performance réseau inter-nœuds en conditions réelles
- Consommation électrique et gestion thermique d'un vrai cluster
2. Stockage distribué impossible à tester
Limitation critique : Le stockage distribué (Ceph, Linstor DRBD, Longhorn avec réplication) nécessite au minimum 3 nœuds pour garantir la redondance :
- Ceph : Requiert 3 nœuds minimum (idéalement 5+) pour le quorum et la réplication
- Linstor DRBD : Nécessite plusieurs nœuds pour la réplication synchrone des données
- Longhorn (réplication) : Ne peut pas répliquer les données sur d'autres nœuds
Conséquences :
- Utilisation du Local Path Provisioner uniquement (stockage non répliqué)
- Pas d'expérience sur la gestion du stockage distribué
- Pas de simulation de panne de disque avec récupération automatique
- Performances limitées (pas de parallélisation des I/O)
Ce qu'on ne peut pas apprendre :
- Configuration et tuning de Ceph (OSDs, MONs, MGRs)
- Gestion des placement groups et crush maps
- Réplication et résilience du stockage
- Performance du stockage distribué vs local
- Stratégies de backup dans un système distribué
3. Scalabilité limitée
Pas de scaling horizontal réel :
- Impossible d'ajouter des nœuds workers pour augmenter la capacité
- Limitations matérielles de la machine unique (CPU, RAM, réseau)
- Pas d'expérience sur l'auto-scaling (Horizontal Pod Autoscaler sur plusieurs nœuds)
Ce qu'on ne peut pas apprendre :
- Ajout et retrait dynamique de nœuds
- Load balancing entre nœuds
- Gestion de la capacité globale du cluster
- Politiques de placement des pods selon les ressources disponibles
4. Réseau simplifié
Pas de simulation de réseau distribué :
- Tous les pods sont sur la même machine physique
- Latence réseau négligeable (pas de simulation réelle)
- Pas de complexité liée aux CNI multi-nœuds
- Pas de VLAN ou segmentation réseau avancée
Ce qu'on ne peut pas apprendre :
- Configuration de CNI avancés (Cilium, Calico avec BGP)
- Network policies complexes entre nœuds
- Performance réseau inter-nœuds
- Gestion des overlays réseau (VXLAN, etc.)
5. Pas de simulation de pannes réalistes
Limitations pour le chaos engineering :
- Impossible de simuler une panne de nœud (on n'a qu'un seul nœud)
- Pas de test de basculement automatique
- Pas de vérification de la reprise après sinistre (DR)
Ce qu'on ne peut pas apprendre :
- Procédures de gestion de crise
- Temps de récupération réels (RTO/RPO)
- Comportement du cluster en situation dégradée
Pourquoi commencer par une version monomachine ?
Malgré les limitations, cette approche présente des avantages significatifs :
1. Coût et simplicité
- Investissement réduit : Pas besoin d'acheter 3-5 serveurs immédiatement
- Consommation électrique : Un seul serveur à alimenter
- Espace physique : Pas besoin de rack ou d'infrastructure réseau complexe
- Maintenance : Moins de machines = moins de pannes potentielles
2. Courbe d'apprentissage progressive
- Complexité maîtrisée : Se concentrer sur Kubernetes sans la complexité multi-nœuds
- Debugging simplifié : Moins de points de défaillance à diagnostiquer
- Erreurs moins coûteuses : Reconfigurer une machine est plus rapide que 5
3. Validation de l'architecture
- Test des services : Vérifier quels services fonctionnent bien sur K8S
- Optimisation des configurations : Affiner les ressources (CPU, RAM) par service
- Identification des problèmes : Détecter les incompatibilités avant de scaler
4. Préparation à l'évolution
Cette version sert de fondation pour le cluster complet :
- Code IaC réutilisable (OpenTofu/Ansible)
- Manifests Kubernetes testés et validés
- Pipelines CI/CD opérationnels
- Documentation complète des processus
Évolution vers un vrai cluster (plan initial)
Si cette version avait été réalisée et stabilisée, l'évolution vers un cluster multi-nœuds aurait été naturelle :
Matériel supplémentaire nécessaire
Minimum pour un cluster HA fonctionnel :
- 3 nœuds (1 control plane + 2 workers, ou 3 nœuds mixtes)
- Switch réseau Gigabit (ou 10GbE pour meilleures performances)
- Stockage distribué (Ceph requiert idéalement 5 nœuds)
Idéal pour tester toutes les fonctionnalités :
- 5 nœuds (3 control plane + 3 workers avec stockage Ceph)
- Switch manageable pour VLAN
- Onduleur (UPS) pour éviter les corruptions de données
Migration progressive
Stratégie de migration prévue :
- Ajouter un deuxième nœud pour former un cluster
- Tester la répartition des pods entre nœuds
- Ajouter un troisième nœud pour le quorum et activer HA (ou utiliser un Qdevice)
- Déployer Ceph ou Linstor pour le stockage distribué
- Migrer les workloads critiques avec réplication
- Configurer les Network Policies avancées
Réutilisation du code existant
Ce qui reste valide :
- Manifests Kubernetes (Deployments, Services, Ingress)
- Configurations Helm
- Pipelines CI/CD
- Scripts d'automatisation Ansible
Ce qui doit être adapté :
- StorageClass : migration vers Ceph/Linstor
- PodDisruptionBudgets : garantir la disponibilité
- Affinité/Anti-affinité : répartir les pods intelligemment
- Configuration réseau : CNI multi-nœuds
Conclusion et évolution vers le cluster 3 nœuds
Ce projet initial de homelab "HA" monomachine a été une réflexion importante dans l'évolution de mon infrastructure :
Points positifs de la réflexion initiale :
- Identification claire des objectifs d'apprentissage Kubernetes
- Validation de l'architecture et des configurations cibles
- Compréhension des limitations d'une approche monomachine
Décision finale : Après avoir analysé les limitations, notamment l'impossibilité de tester les aspects distribués (haute disponibilité, stockage Ceph, répartition de charge), j'ai décidé d'opter directement pour un cluster Proxmox 3 nœuds.
Cette décision permet :
- D'expérimenter avec de vraies VMs K3S réparties sur les nœuds physiques de production
- De tester la haute disponibilité et le stockage distribué (Ceph)
- D'apprendre les aspects réseau complexes d'un cluster réel
- De construire une base solide pour une infrastructure prête pour la production
Pour plus de détails sur l'architecture finale retenue, voir la page Cluster 3 noeuds Proxmox.